Matriz de Confusão e Métricas de Desempenho
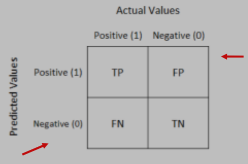
A matriz de confusão é uma ferramenta importante para avaliar o desempenho em problemas de classificação binária, fornecendo uma maneira visual de comparar os resultados reais com as previsões do modelo. A matriz é composta por quatro componentes: True Positives (TP), True Negatives (TN), False Positives (FP) e False Negatives (FN). Com base nessa matriz, várias métricas de desempenho podem ser calculadas:
-
Acurácia (Accuracy):
- Acurácia é a proporção de previsões corretas (TP + TN) em relação ao total de casos (TP + TN + FP + FN). É uma medida geral do desempenho do modelo.
- Exemplo: ((629 + 1231) / (1231 + 146 + 394 + 629) = 77.5%)
-
Sensibilidade (Sensitivity) ou Recall:
- Sensibilidade é a proporção de casos positivos reais que são corretamente previstos como positivos (TP / (TP + FN)). É útil para identificar a capacidade do modelo de detectar casos positivos.
-
Especificidade (Specificity):
- Especificidade é a proporção de casos negativos reais que são corretamente previstos como negativos (TN / (TN + FP)). É importante para avaliar a capacidade do modelo de detectar corretamente casos negativos.
-
Precisão (Precision):
- Precisão é a proporção dos casos positivos previstos que são realmente positivos (TP / (TP + FP)).
-
F1 Score:
- F1 Score é a média harmônica de precisão e recall. É útil quando precisão e recall são muito diferentes e tende a se aproximar do menor número comparado ao maior valor.
Essas métricas fornecem informações diferentes e complementares sobre o desempenho do modelo. Sensibilidade e precisão são especialmente importantes, pois proporcionam uma compreensão sobre quantos casos positivos foram perdidos (sensibilidade) e quantos foram corretamente capturados (precisão). O trade-off entre essas métricas é um aspecto crítico na avaliação de modelos de classificação binária.